NOVEMBER 2024
HOW MACHINES WERE TAUGHT TO 'SPEAK'.
SUMMARY.
The evolution of language processing spans from Aristotle’s early theories to the development of modern Natural Language Processing (NLP). Key advancements, including the perceptron and machine learning, enabled computers to enhance their performance by analysing data. Ultimately, systems like Gemini, or ChatGPT, can answer questions due to advanced algorithms that treat words as mathematical representations of reality, rather than through human-like understanding.
EARLY ATTEMPTS.
Language is one of the most defining cognitive traits that sets humans apart from other species. Since ancient times, philosophy has been deeply engaged in exploring its origins, nature, and limitations, as well as its complex relationship with empirical reality — issues that continue to spark lively debate to this day.
In the 4th century B.C., the Greek philosopher Aristotle not only emphasised the central role of λόγος (logos) as a medium of communication but also tackled the long-standing question of how it intersects with human cognition.
A crucial aspect of his linguistic inquiry, found in the second text of his Organon, De Interpretatione, is the concept of language as a formal system governed by specific logical rules.
For Aristotle, language serves as an essential tool for understanding the sensible world because its structure mirrors the structure of thought: words are the fundamental units of logical reasoning.
Building on this philosophical tradition, in the 17th century, Gottfried Wilhelm von Leibniz – famous for developing the notation for calculus still in use today – envisioned a universal artificial mathematical language capable of expressing all human knowledge.
In his visionary system, strict rules of calculation would define the logical relations between propositions.
Leibniz even foresaw the creation of specialised machines to perform these calculations.
The analogy between natural language and logic, or algebraic language, became a major scientific concern and laid the groundwork for Natural Language Processing (NLP), an interdisciplinary field that has evolved since the 1940s at the crossroads of linguistics and computer science.
NLP seeks to teach machines to analyse, process, and generate human language.
With the advent of ‘calculators’, language was increasingly seen as a fully computational problem: if it could be formalised through logic, it could then be translated into a set of algebraic commands for execution by a computer.
Early efforts in this area involved symbolic artificial intelligence (symbolic AI, or GOFAI – “Good Old-Fashioned Artificial Intelligence”), which gained intellectual prominence until the 1970s.
Symbolic AI was based on the idea that human knowledge consists of an ordered set of words, combined into sentences (symbols), which could be organised into a series of computational rules for machines to analyse and perform tasks.
Symbolic AI systems, such as rule-based machine translation programs, were capable of translating simple sentences.
However, they struggled with idiomatic expressions, context, and nuance.
For instance, if the system did not understand that over the moon is an English expression meaning being delighted, it might produce a nonsensical literal translation when converting it to another language.
This highlighted a larger problem: the initial reliance on formal logic did not account for the inherent ambiguity of natural language.
�
A NEUROSCIENCE-LIKE APPROACH.
A more complex and multifaceted approach was required, leading to the development of machine learning – the process by which computers improve their ability to perform tasks by analysing new data, without the need for human-generated instructions in the form of a program.
Psychologist Frank Rosenblatt tried to solve the problem by taking inspiration directly from neuroscience.
In 1958, he theorised the perceptron, a sort of calculational neuron (and the ancestor of current artificial neurons).
A neuron is a cell within the human brain that receives and exchanges electrical or chemical signals with the other neurons to whom it is connected: its activation is determined by the sum of the inputs received (having different levels of strength according to the weight of the connection) which has to reach a specific threshold in order to trigger its activation.
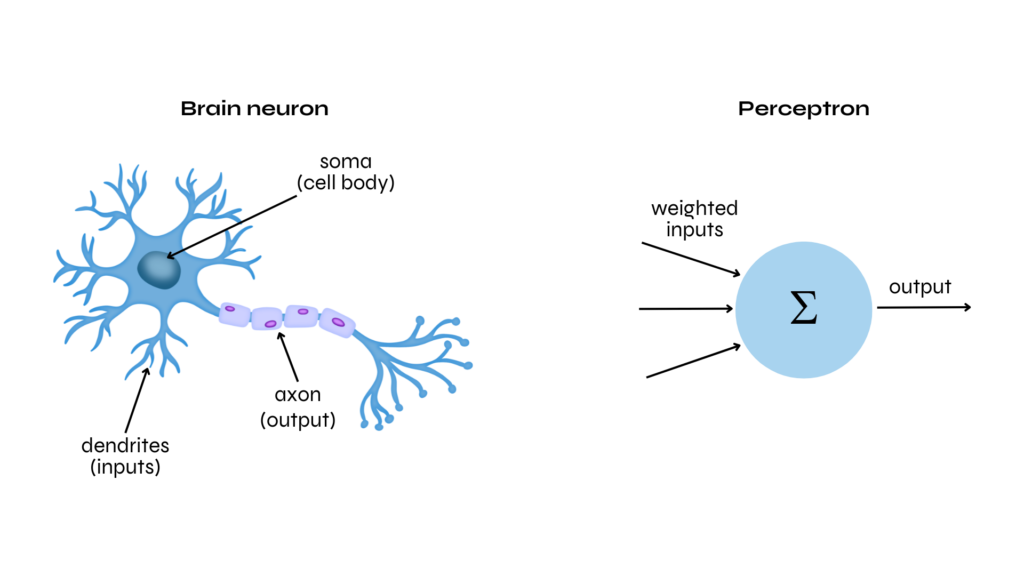
Similarly, the perceptron takes several inputs and combines them taking into account their weights. It then adds these weighted inputs together. This sum is passed through a function that decides whether the output should be one value (like 1) or another (like 0), based on a certain threshold.
This process is achieved through training: the perceptron network is given inputs and makes a guess about the output.
Then, the programmer provides feedback, indicating how far the guess is from the correct answer.
Based on this, the perceptron adjusts its weights and thresholds automatically.
However, since the perceptron is a linear classifier, it can only separate data that can be divided by a straight line.
A classic example of this limitation is the XOR problem, a binary logic function that returns true (1) only if one of the two inputs is true (1), but not both.
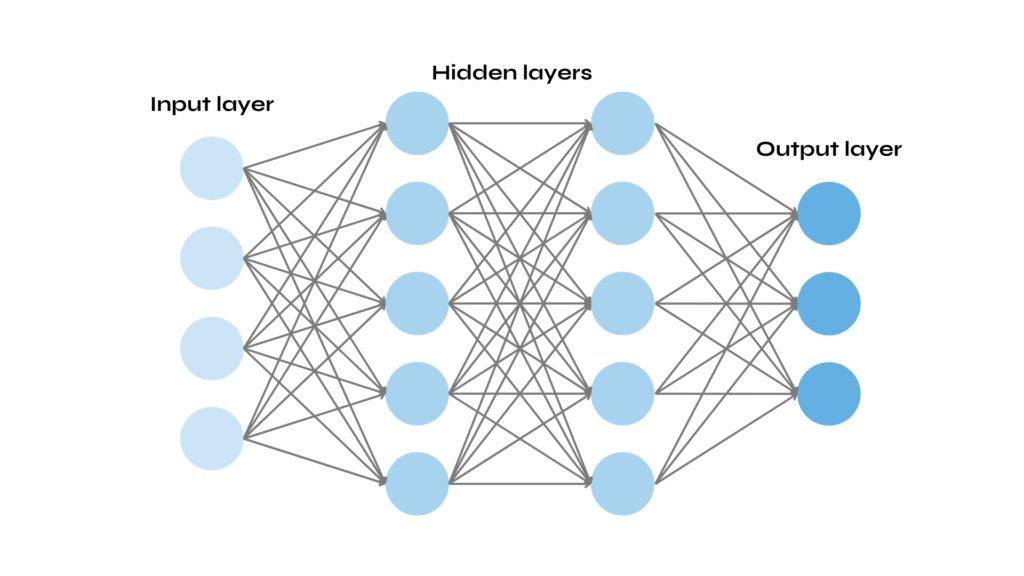
However, researches found out how adding a layer could significantly improve performance: this type of architecture is called ‘connectionist networks’ (artificial neural networks, ANN).
WORD EMBEDDINGS.
The inputs of the neurons that compose a neural network have to be numerical values in order to be summed up and multiplied by their weights.
Clearly, this raises a problem of a structural sort, for words have to be converted into numbers.
Hence, from distributional semantics, based on the quote «you shall know a word by the company it keeps», an algorithm was developed in the 2010s.
It aimed at encoding words by capturing the semantic relationship linking them to others.
By converting them into geometric points within a three-dimensional semantic space, each word can be identified by its coordinates – its position in the x, y and z axis (e.g. word2vec).
This approach is usually referred to in NLP as a vector of words, or word embedding, and it currently constitutes the foundations of the architecture behind most language models.

Deep learning and word embeddings provided a crucial boost to the field of NLP, although more advanced versions of these architectures are now used.
During the 2010s, voice assistants like Siri (developed by Apple Inc.) and Alexa (integrated by Amazon.com, Inc.) emerged, as did machine translation programs like Google Translate (developed by Google LLC) and a variety of other NLP applications.
In conclusion, it’s not magic that ChatGPT can answer questions; it’s the result of algorithms we’ve developed over time.
For language models, words are not imbued with meaning in the way humans experience them; they are simply mathematical representations of a reality they do not truly “know.”
The underlying processes and advancements in NLP, deep learning, and machine learning allow them to predict and generate language based on patterns, rather than understanding or experiencing the world as humans do.
REFERENCES.
Cristianini, N. (2023). La scorciatoia: come le macchine sono diventate intelligenti senza pensare in modo umano. Il mulino.
Jones, K. S. (1994). Natural language processing: a historical review. Current issues in computational linguistics: in honour of Don Walker, 3-16.
Mitchell, M. (2019). Artificial intelligence: A guide for thinking humans.
Rosenblatt, F. (1958). The perceptron: a probabilistic model for information storage and organization in the brain. Psychological review, 65(6), 386.